아래 내용은 서준석 저자의 "인공지능 보안을 배우다"에서 참고하여 정리한 내용입니다.
우선 2가지 인공지능 알고리즘을 사용한다는 것을 배웠는데
분류/군집화 알고리즘, CNN 알고리즘을 사용한다고 한다.
위의 내용들을 아래에 정리해보자.
분류 알고리즘
- 다중 클래스 분류 학습 시 여러 개의 카테고리를 그대로 사용하는 방법도 있지만, 1 vs All 방식을 사용하는 것도 가능
1. 모델 1(A vs all): B, C, D 유형을 모두 X로 변환 후 이진 분류 학습(A or X)
1. 모델 2(B vs all): A, C, D 유형을 모두 X로 변환 후 이진 분류 학습(B or X)
1. 모델 3(C vs all): A, B, D 유형을 모두 X로 변환 후 이진 분류 학습(C or X)
1. 모델 4(D vs all): A, B, C 유형을 모두 X로 변환 후 이진 분류 학습(D or X)
아래는 분류 알고리즘인 3개의 대표적인 알고리즘이다.
1. 나이브 베이즈
: 특징들 사이의 독립성을 가정으로 하는 베이즈 정리를 토대로 데이터를 분류하는 알고리즘
학습에 사용하는 모든 특징이 서로 독립적이라는 전제
특징의 확률을 구하는 방법에는 가우시안(Gaussian), 다항분포, 베르누이 방식이 있음
| 장점 | 1. 학습 데이터의 양이 적은 상황에서 좋은 성능을 보여줌 2. 적절한 전처리만 거치면 서포트 벡터 머신이나 랜덤 포레스트와 같이 진보된 알고리즘에도 뒤지지 않는 성능을 보여줌 3. 많은 특징을 사용할 때 발생하는 '차원의 저주'문제에 영향을 받지 않음 |
| 단점 | 1. 모든 특징이 독립적이라는 전제를 가지고 있다는 점 |
단, 정보의 양은 단순 총합으로 계산되는 것이 아니라는 것이 중요한데,
종속관계를 가지는 특징 조합이 생기는지, 상관성이 매우 높은 특징 조합이 생길 수도 있기 때문이다.
2. 의사 결정 트리와 랜덤 포레스트
의사 결정 트리
: 의사결정 규칙을 트리 구조로 나타내 전체 자료를 몇개의 소집단으로 분류하거나 예측할 수 있는 분석 방법
최적의 트리를 찾는 것에 초점을 맞춤(기존에는 최적의 선을 찾는 것에 초점을 맞췄음)
내부 알고리즘에는 ID3, C4.5, C5.0, CART 가 있음
최초 질문에서 시작해 가장 좋은 결과를 보장하는 방향으로 트리를 확장하는 방법을 다룸
| 장점 | 해석 가능성 |
| 단점 | 1. 그만큼 복잡한 문제를 다루는 데는 좋은 성능을 발휘하지 못한다. 2. 특징 데이터가 조금만 달라져도 완전히 다른 트리가 만들어 질 수 있다. |
랜덤 포레스트
: 앙상블 기반 알고리즘 중 하나로, 여러 개의 의사 결정 트리를 만든 후 각 트리의 결과를 다수결로 결정하는 배깅 방식으로 의사 결정 트리의 성능을 개선하는 대표적인 모델
전체 데이터에서 무작위로 여러 개의 하위 데이터를 추출한 후 이를 사용해 여러 개의 모델을 만듦, 전체 데이터를 하나의 모델로 만들면 분류에 가장 도움이 되는 특징을 위주로 트리를 만들게 됨
| 장점 | 1. 학습 데이터에서는 큰 비중이 없는 특징이라고 해도, 새롭게 유입되는 데이터에서는 중요한 역할을 할 수 있고, 이런 부분들도 포착해내는 큰 장점을 가짐 2. 중요도, 분류에 가장 많이 도움되었던 특징을 백분율로 계산해줌 3. 옵션 값 조합만 잘 찾아도 꽤 높은 정확도를 보여주는 모델을 만들 수 있다. |
| 단점 | 1. 학습에 사용하는 데이터의 특성에 따라 항상 최적의 해를 보장해주지 못함 2. 데이터의 양이 늘어나도 그만큼 성능이 향상된다는 보장을 해주지 못함 |
앙상블 기법의 장점을 최대한 발휘하는 모델을 만들고 싶다면 각 파라미터가 의미하는 바를 정확히 이해하고,
학습에 사용할 데이터와 학습 목적에 맞는 최적의 파라미터 값 조합을 찾아야 함
3. 서포트 벡터 머신(SVM)
: SVM은 분류하려는 두 영역을 하나의 선으로 나누었을 때,
그 선이 양쪽에 위치한 점들과의 거리가 최대가 되도록 만드는 것이 목표
불과 몇 년 전까지만 해도 독보적인 비중을 차지했던 가히 최고의 머신러닝 알고리즘 중 하나로 꼽힘
하루가 다르게 새로운 딥러닝 모델이 쏟아지고 있는 지금에도, 여전히 많은 분야에서 활용되고 있는 알고리즘
2가지 방식이 존재하는데,
1. 선형 분리 기반의 서포트 벡터 분류기를 사용하는 방식
2. 선형으로 분리할 수 없는 데이터를 커널 트릭을 사용해 마치 선형 분류처럼 처리하는 방식
→ 이때 커널 트릭이란, 새로운 특징을 토출해 데이터를 고차원 공간으로 사영해 구분 짓는 방법
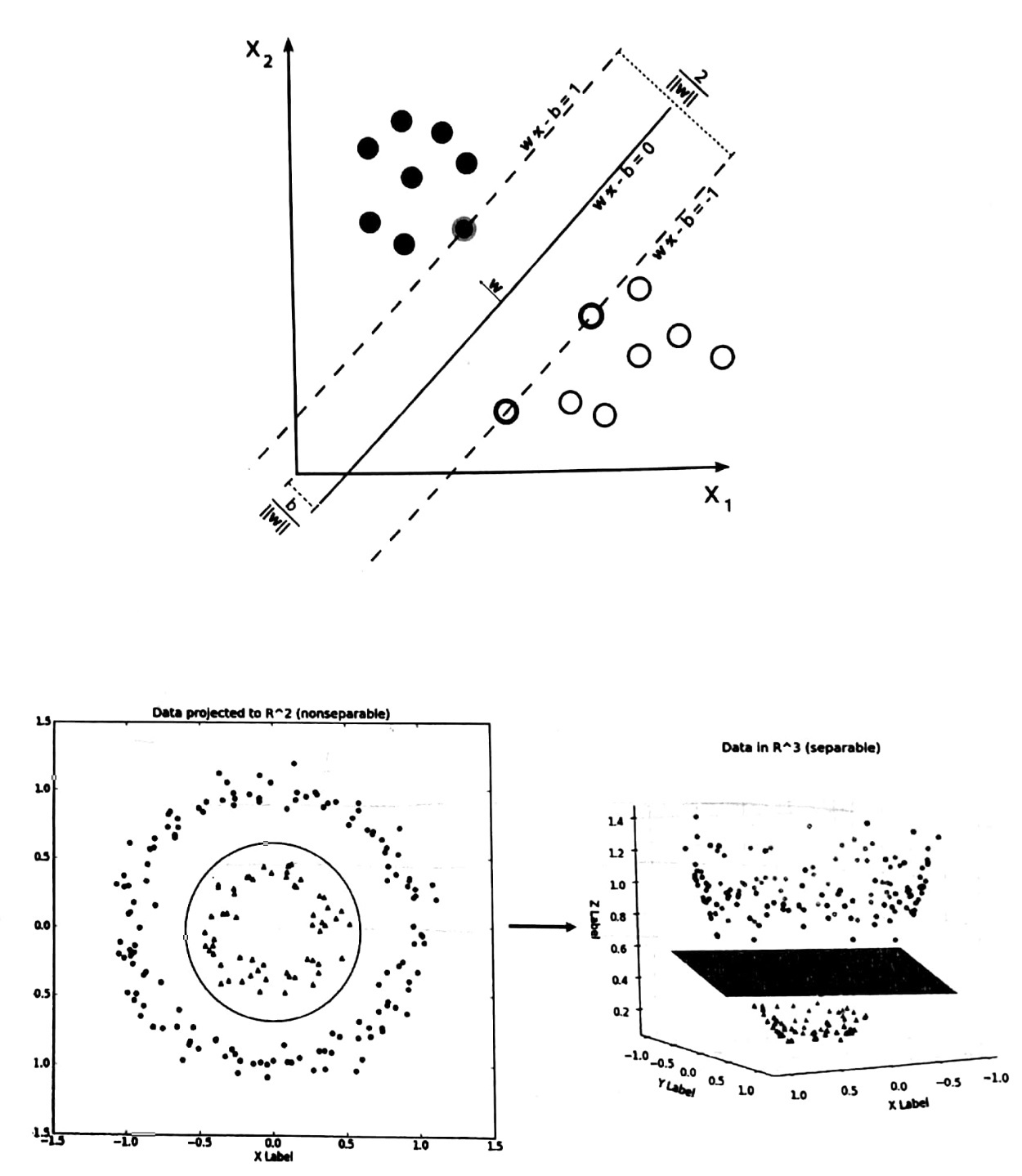
| 장점 | 1. 고차원 문제 해결에 용이하며, 노이즈 데이터에 크게 영향을 받지 않고, 과적합 문제도 어느 정도 해결 가능 |
| 단점 | 1. 최적의 모델을 위해선 앞서 언급한 최적의 파라미터 조합을 반드시 찾아야 함 |
군집화 알고리즘
- 카테고리를 모르는 상태에서 데이터만으로 유사한 패턴을 가진 군집을 찾아내는 방식을 의미함
- 다양한 정보를 담고 있는 수많은 데이터들 간의 일정한 패턴을 찾아내는 것이 군집화 학습의 목표
- 군집화 알고리즘에는 아래와 같은 유형이 있음
1. 연결성 기반: 데이터 사이의 거리 연결성을 중심으로 군집화(hierarchical 클러스터링)
2. 중심 기반: 평균 벡ㅌ를 기준으로 군집화(K-means 클러스터링)
3. 분포 기반: 확률 분포를 기반으로 군집화(EM 알고리즘, multivariate 정규 분포)
4. 밀도 기반: 데이터 공간 내의 연결된 밀집 영역을 기준으로 군집화(DBSCAN)
5. 그래프 기반: 데이터를 그래프로 표현한 후 서로 연결된 가까운 노드를 군집화(HCS 클러스터링)
- 카테고리에 대한 정보가 없는 상태에서 학습을 하는 알고리즘의 특성 상 결과가 매우 불안정하며, 군집을 찾아내는 방식에 따라 그 결과 또한 다양하게 나타날 수 있음
- 수많은 형태와 변종이 있는 악성코드를 단순히 악성과 정상으로 분류하는 것보다 나름의 특성을 고려해 유사한 샘플들을 군집화한 후 개별 특성에 맞는 분류 알고리즘으로 탐지하는 방법도 있음
아래는 군집화 알고리즘인 3개의 대표적인 알고리즘이다.
1. K-means 클러스터링
: 주어진 데이터를 K개의 클러스터로 만들어 줌 분석가가 몇 개(K)의 군집을 만들 것인지 명시해야함
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
Visualizing K-Means Clustering
January 19, 2014 Suppose you plotted the screen width and height of all the devices accessing this website. You'd probably find that the points form three clumps: one clump with small dimensions, (smartphones), one with moderate dimensions, (tablets), and
www.naftaliharris.com
위 사이트에서 K-means 클러스터링을 시연해볼 수 있다!
평균값을 기준으로 중심을 결정하는 K-means 클러스터링은 충분히 많은 데이터가 있을 경우 유사한 속성을 가진 데이터끼리 몰려 중심을 형성하고, 이 중심을 기준으로 나름의 분포를 형성할 것이라는 전제로 동작함
| 장점 | 1. 구현이 쉽고 빠름 |
| 단점 | 1. 최적의 K 값을 결정하기가 어려움 2. 학습 결과가 항상 동일한 결과를 보장하지 않음 3. 이상치에 민감함 |
2. DBSCAN
: 확률 밀도 기반 클러스터링 알고리즘으로, 데이터가 몰려있는 밀도가 높은 부분을 군집화하는 방식을 사용
반경 x 거리 내에 점이 n개 이상있으면 하나의 군집으로 인식하는 방법
DBSCAN을 사용하기 위해 아래의 2개의 정보를 정해줘야함
1. 점 사이의 최대 거리(ε)
2. 이 거리 내에 있는 최소의 점의 개수(minPts)
| 장점 | 1. 군집의 개수를 임의로 지정하지 않아도 기하학적인 모양의 클러스터도 높은 정확도로 분류할 수 있음 2. 점들 사이의 밀도를 기준으로 군집을 형성해 이상치에도 강함 |
| 단점 | 1. DBSCAN도 여타 클러스터링 알고리즘과 마찬가지로 최적의 ε과 minPts값을 찾아야 함 2. 데이터들이 충분한 수준의 밀도를 형성하지 않는 경우 오히려 정확도가 낮게 나올 수 있음 |
3. 주성분 분석(Principal Component Analysis)
: 특징 공간에서 주성분이 되는 축을 찾아 이 축을 기준으로 데이터를 변환해 특징의 개수를 줄여주는 알고리즘
비지도 학습의 꽃이자, 가장 중요한 알고리즘으로,
주성분 분석은 데이터를 한 개의 축으로 축소했을 때 그 분산이 가장 커지는 축을 첫 번째 주성분,
두번째로 커지는 축을 두 번쨰 주성분으로 놓이도록 데이터를 변환함
이때 분산이 가장 커지는 축이라는 것은 오류를 최소화할 수 있는 기준선을 의미함
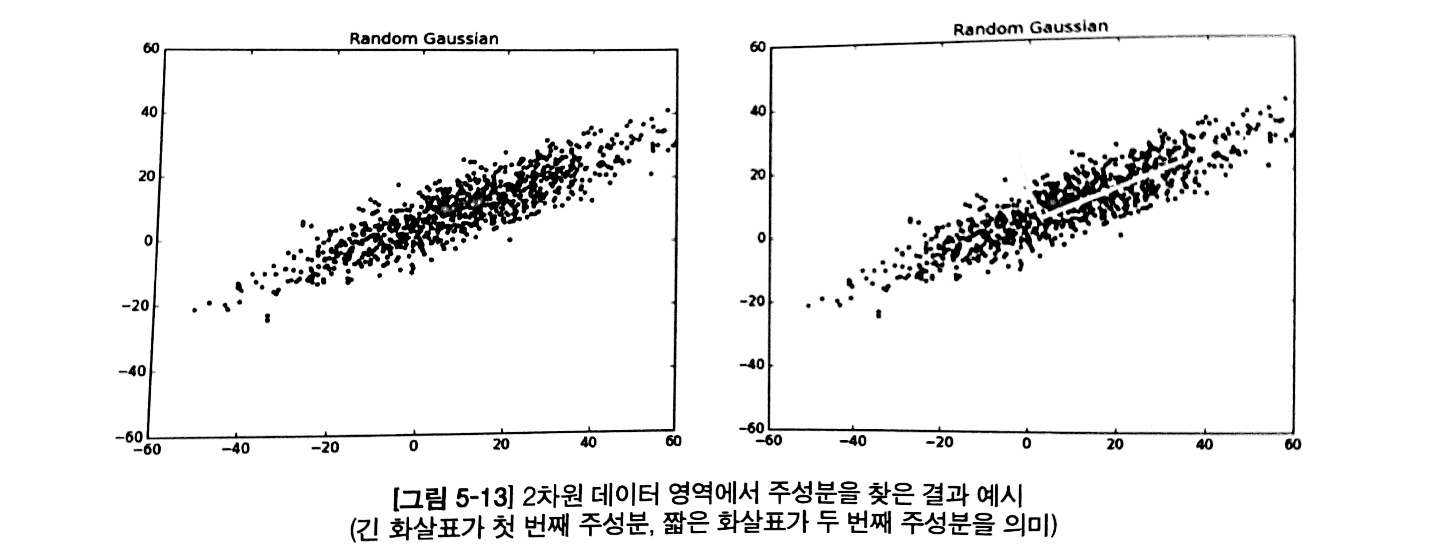
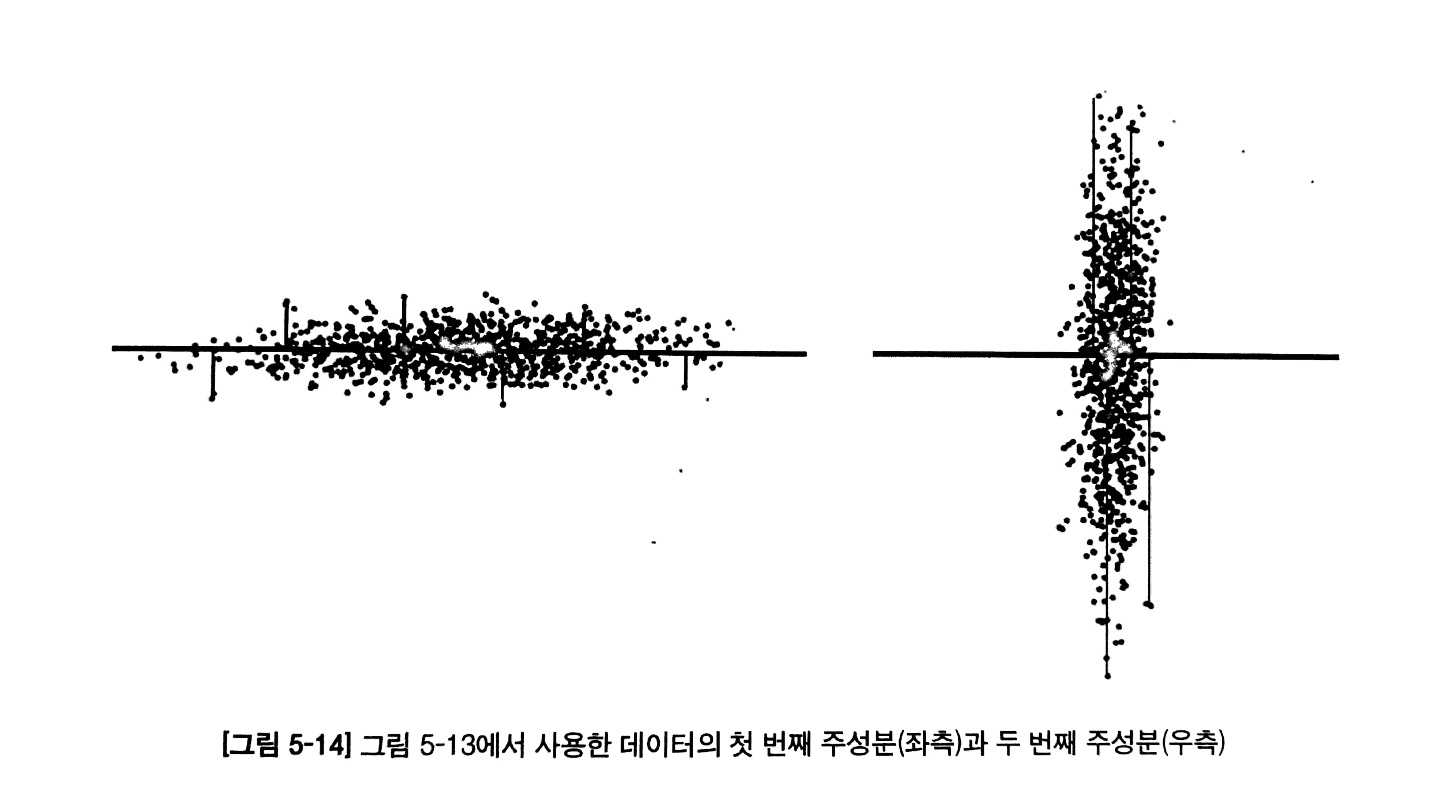
주성분이라함은 직선을 그은 후 모든 점을 해당 직선에 붙일 때, 그 거리가 최소가 되는 직선을 의미한다.
쉽게 말해서, 점을 이동시켜 직선에 붙인다는 의미는 그만큼 데이터가 가진 정보를 버리겠다는 의미이다.
모든 점들이 이동하는 거리가 최소가 되는 직선이 정보의 손실이 가장 작은 축이 될 것이고,
이는 곧 이 직선이 가장 많은 정보를 담을 수 있는 주성분이 되는 것이다.
두 번째 주성분 또한 정보의 손실을 최소화하는 중심 선을 의미한다.
이때, 첫번째 주성분과 직교한 직선이 두 번째 주성분이 되고(그림 5-14의 우측 그림),
이 주성분은 첫 번째 주성분 다음으로 정보의 손실을 최소화하면서 데이터를 이동시키는 기준 축이 된다.
카테고리 없이 데이터 자체만으로 핵심이 되는 성분을 파악할 수 있기 때문에,
이를 사용하여 전체 데이터에서 가장 중요한 기준선들을 찾아낼 수 있다.
딥러닝 알고리즘

- CNN
입력 데이터를 이미지처럼 정형화된 크기로 만들 수만 있다면 나머지는 CNN에 맡기기만 하면 됨
즉, 이미지화 한 후 어떤 데이터를 탐지하도록 할 수 있음
- RNN
시계열 데이터, 즉 인과 관계가 있고 시간 흐름이 있는 데이터를 처리할 수 있는 모델
네트워크 안에 위치한 노드들이 다양한 방향으로 연결되어 있음
특징들 간의 순서를 토대로 악성 여부를 결정함
- GAN
새로운 데이터를 생성해내는 혁신적인 모델
분류기: 분류를 잘하도록 학습하는 것
생성기: 분류기가 분류하지 못하는 데이터를 만들어내는 목적
이를 잘 활용하면, 탐지모델을 우회하는 새로운 모델을 만들어낼 수 있음
아래는 CNN에 대한 설명이 기록되어 있음
3. CNN(Convolutional Neural Network)
: 이미지에서 특징을 자동으로 추출해주는 모델
하나의 이미지에서 수천 개가 넘는 특징을 빠르게 추출할 수 있음
CNN은 크게 특징을 추출하는 부분(Convolutional Layer)과 추출한 특징을 사용해 판단을 내리는 부분으로 나눠짐
이때 특징을 추출할 때는 다양한 필터를 사용해 이미지 전체를 스캔하듯이 사진을 찍는 방식을 사용
결론적으로 데이터 크기를 정형화할 수 있는 방법만 있다면 모든 보안 분야에 CNN을 적용할 수 있음
'AI > ML Basic' 카테고리의 다른 글
| 머신러닝 EP5. 강화학습 (0) | 2021.12.22 |
|---|---|
| 머신러닝 EP4. 비지도학습 (0) | 2021.12.22 |
| 머신러닝 EP3. 지도학습 (0) | 2021.12.22 |
| 머신러닝 EP2. 표와 머신러닝의 카테고리 (0) | 2021.07.14 |
| 머신러닝 EP1. 교양 (0) | 2021.07.12 |



댓글