변수가 여러 개일 경우(multi-variable)의 선형 회귀는 어떻게 할까?
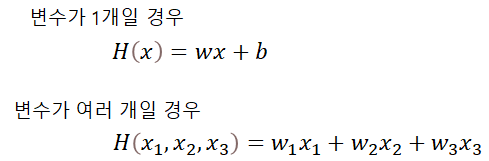
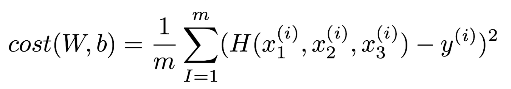
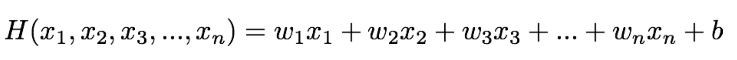
Matrix를 이용해 표현하자!
이때 matrix를 사용하면 X가 앞으로 오고, 대문자로 표현하는 특징이 있다.
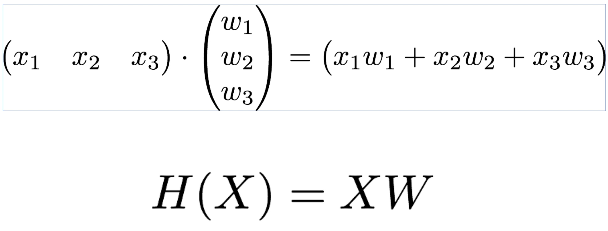
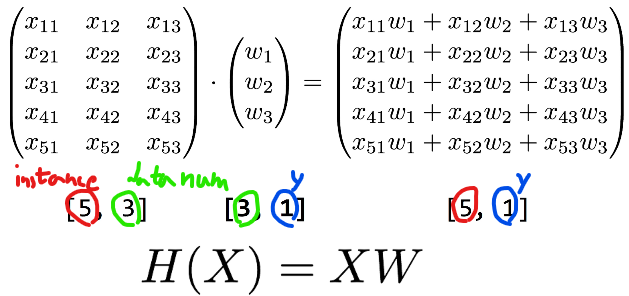
보통 다음과 같은 식이 계속해서 나오는데 X와 H(X)는 주어지는 경우가 많다.
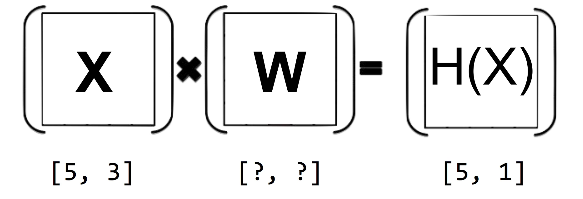
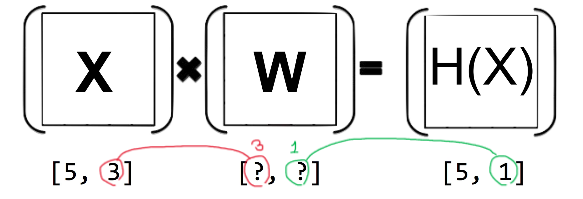
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
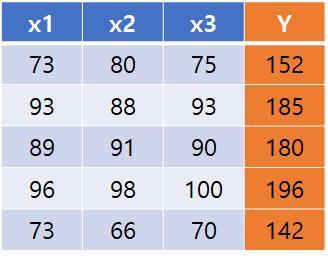
x1_data = [73., 93., 89., 96., 73.]
x2_data = [80., 88., 91., 98., 66.]
x3_data = [75., 93., 90., 100., 70.]
y_data = [152., 185., 180., 196., 142.]
#placeholder를 통해 여러 데이터를 저장함
x1 = tf.placeholder(tf.float32)
x2 = tf.placeholder(tf.float32)
x3 = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
w1 = tf.Variable(tf.random_normal([1]), name = 'weight1')
w2 = tf.Variable(tf.random_normal([1]), name = 'weight2')
w3 = tf.Variable(tf.random_normal([1]), name = 'weight3')
b = tf.Variable(tf.random_normal([1]), name = 'bias')
hypothesis = x1 * w1 + x2 * w2 + x3 * w3 + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train], feed_dict={x1: x1_data, x2: x2_data, x3: x3_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)위의 코드는 matrix를 사용하지 않은 코드이다.
아래의 코드는 matrix를 사용하여 코드에서 입력 데이터와 관련된 코드를 단순화 시킨다.
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
#using matrix
# x1_data = [73., 93., 89., 96., 73.]
# x2_data = [80., 88., 91., 98., 66.]
# x3_data = [75., 93., 90., 100., 70.]
x_data = [
[73., 80., 75.],
[93., 88., 93.],
[89., 91., 90.],
[96., 98., 100.],
[73., 66., 70.],
]
y_data = [[152.], [185.], [180.], [196.], [142.]]
#placeholder를 통해 여러 데이터를 저장함
# x1 = tf.placeholder(tf.float32)
# x2 = tf.placeholder(tf.float32)
# x3 = tf.placeholder(tf.float32)
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
#using matrix at weight
# w1 = tf.Variable(tf.random_normal([1]), name = 'weight1')
# w2 = tf.Variable(tf.random_normal([1]), name = 'weight2')
# w3 = tf.Variable(tf.random_normal([1]), name = 'weight3')
W = tf.Variable(tf.random_normal([3, 1]), name = 'weight')
b = tf.Variable(tf.random_normal([1]), name = 'bias')
#hypothesis = x1 * w1 + x2 * w2 + x3 * w3 + b
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
이번에는 데이터가 파일에 저장되어 있다면 어떻게 load 후 사용할지 생각해보자
import numpy as np
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
tf.set_random_seed(777) #재현성을 위한 코드
#load data from file
xy = np.loadtxt('data-01-test-score.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
print(x_data.shape, x_data, len(x_data))
print(y_data.shape, y_data)
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name = 'weight')
b = tf.Variable(tf.random_normal([1]), name = 'bias')
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
#Ask my score
print("Your score will be", sess.run(hypothesis, feed_dict={X: [[100, 70, 101]]}))
print("Other scores will be", sess.run(hypothesis, feed_dict={X: [[60, 70, 110], [90, 100, 80]]}))
그럼 이제 만약 데이터의 개수가 수도 없이 많다면,
그래서 메모리의 크기를 넘어선다면 어떻게 해결할지 생각해보자
우선 아래의 구조를 살펴보자.
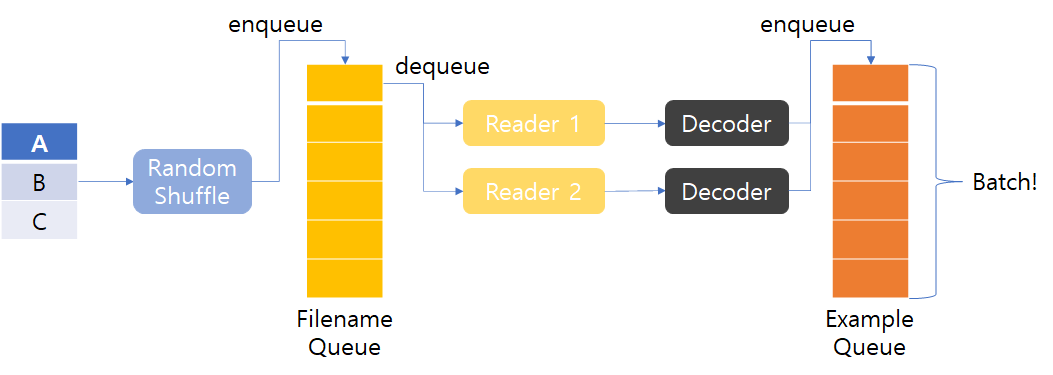
간단히 설명하자면 Example Queue에 데이터를 쌓아놓고,
Batch size를 주어 필요한 데이터 만큼 Queue에 쌓은 후 사용하는 것이다.
즉, 아래와 같은 순서로 데이터를 꺼내 사용하게 된다.
1. 각각의 Reader가 파일로부터 데이터를 읽는다.
2. Decoder가 읽은 데이터를 example, label에 맞게끔 매핑한다.
3. Example Queue에 Batch size만큼 쌓아놓고 학습에 사용한다.
batch와 관련된 글은 아래 사이트에 잘 정리되어 있다.
https://blog.lunit.io/2018/08/03/batch-size-in-deep-learning/
Batch Size in Deep Learning
딥러닝 모델의 학습은 대부분 mini-batch Stochastic Gradient Descent (SGD)를 기반으로 이루어집니다. 이 때 batch size는 실제 모델 학습시 중요한 hyper-parameter 중 하나이며, batch size가 모델 학습에 끼치는 영
blog.lunit.io
또한, 위와 같은 구조에서 데이터를 load하는 쓰레드에 대한 관리를 어떻게 하는지는,
아래의 Coordinator와 관련된 글을 참고하라.
https://tensorflowkorea.gitbooks.io/tensorflow-kr/content/g3doc/how_tos/threading_and_queues/
쓰레드와 큐 · 텐서플로우 문서 한글 번역본
tensorflowkorea.gitbooks.io
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
#filename queue 만들기
filename_queue = tf.train.string_input_producer(['data-01-test-score.csv'], shuffle=False, name='filename_queue')
#reader 블록 만들기
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
#csv로부터 읽은 데이터에 대한 포맷 정하기
record_defaults = [[0.], [0.], [0.], [0.]]
xy = tf.decode_csv(value, record_defaults=record_defaults)
#batch size 정하기 메모리를 효율적으로 사용하기 위한 방법
train_x_batch, train_y_batch = tf.train.batch([xy[0:-1], xy[-1]], batch_size = 10)
# batch shuffle을 할 수 있는 함수도 있으니 참고
# min_after_dequeue = 10000
# capacity = min_after_dequeue + 3 * batch_size
# example_batch, label_batch = tf.train.shuffle_batch([example, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue)
#====================same with lab4-2.py====================
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name = 'weight')
b = tf.Variable(tf.random_normal([1]), name = 'bias')
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#===========================================================
#coord는 일종의 쓰레드 관리자 쓰레드를 모두 정지시킬 때 사용함
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for step in range(2001):
x_batch, y_batch = sess.run([train_x_batch, train_y_batch])
cost_val, hy_val, _ = sess.run([cost, hypothesis, train], feed_dict={X: x_batch, Y: y_batch})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
coord.request_stop()
coord.join(threads)'AI > 모두를 위한 딥러닝 정리' 카테고리의 다른 글
| Day6. Softmax (0) | 2022.04.11 |
|---|---|
| Day5. Logistic Classification과 Logistic Regression (0) | 2022.04.01 |
| Day3. Gradient descent algorithm (0) | 2022.03.05 |
| Day2. regression의 원리와 간단한 구현 (0) | 2022.02.28 |
| Day1. Machine Learning에서 사용하는 단어 (0) | 2022.02.26 |




댓글